
STX B+ Tree C++ Template Classes
| TalkBox |
| a) also ich verstehe diesen "Sicherheits"-Einwand auch nicht |
| Ein paar Worte zu deinen drei Punkten: Ja, die Implementierung macht natürlich eine binäre Suche auf den sortierten Schlüsselwerten in einem Knoten. Jedoch würde ich binäre Bäume nicht als Sicherheitsrisiko, sondern als Performance- oder Skalierungsproblem bezeichnen. Der B-Baum verbraucht verglichen mit dem Binärbaum zwar insgesamt mehr Speicher, aber immer in zusammenhängenden Blöcken. Ob virtuellen oder realen Speicher ist erstmal egal. Durch die größeren Speicherblöcke wird die L1/L2 Cache-Hitrate verbessert, dies zu zeigen war eines der Ausgangspunkte, wie auch in der Zusammenfassung steht. Was an dem direkten Vergleich "unfair" sein soll verstehe ich nicht. Er war Ausgangsüberlegung der Arbeit. Darüber steht aber viel mehr im englischen Text. |
| Der Performance-Vergleich ist etwas unfair gegenüber den Binär-Bäumen. Wäre schön, wenn folgende Punkte Erwähnung fänden:
|
Posted on 2007-04-27, last updated 2013-05-05 by Timo Bingmann at Permlink.
Summary
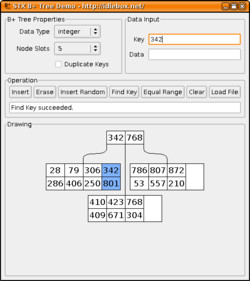
The STX B+ Tree package is a set of C++ template classes implementing a B+ tree key/data container in main memory. The classes are designed as drop-in replacements of the STL containers set, map, multiset and multimap and follow their interfaces very closely. By packing multiple value pairs into each node of the tree the B+ tree reduces heap fragmentation and utilizes cache-line effects better than the standard red-black binary tree. The tree algorithms are based on the implementation in Cormen, Leiserson and Rivest's Introduction into Algorithms, Jan Jannink's paper and other algorithm resources. The classes contain extensive assertion and verification mechanisms to ensure the implementation's correctness by testing the tree invariants. To illustrate the B+ tree's structure a wxWidgets demo program is included in the source package.
The STX B+ Tree package is now obsolete (2019), because an improved version with better STL semantics is contained the new TLX library of C++ containers and algorithms.
The main B+ tree implementation can be found in doxygen stx/btree.h or with plain text comments btree.h.
Special interest was put into performing a speed comparison test between the standard red-black tree and the new B+ tree implementation. The speed test results are interesting and show the B+ tree to be significantly faster for trees containing more than 16,000 items on a Pentium 4 and more than 100,000 items on an Intel Core i7 CPU.
The B+ tree main header code is covered to 90.3% by test cases. A graphical display of the test suite's coverage can be viewed online.
The package includes a demo program, which illustrates how the B+ tree organises integer and string keys. Compiled binaries for Windows and and some Linux distributions are available on the demo download page.
See the README file below for a more detailed overview. See ChangeLog below on what changed in version 0.9.
Downloads
| STX B+ Tree Version 0.9 (current) released 2013-05-05 | ||
| Source code archive: (includes Doxygen HTML) | stx-btree-0.9.tar.bz2 | Browse online |
| ChangeLog | ||
| Extensive Documentation: | Browse documentation online | |
| Demo Binaries: | See Extra Download Page for Win32 and Linux binaries. | |
See bottom of this page for older downloads.
License and Git Repository
The B+ tree template source code is released under the Boost Software License, Version 1.0, which can be found at the header of each include file.
All auxiliary programs like the wxWidgets demo, test suite and speed tests are licensed under the GNU General Public License v3 (GPLv3).
The git repository containing all sources and packages is available bygit clone https://github.com/bingmann/stx-btree
Some further papers, documentation and some future branches are also available there.
README
Original Idea
The idea originally arose while coding a read-only database, which used a huge map of millions of non-sequential integer keys to 8-byte file offsets. When using the standard STL red-black tree implementation this would yield millions of 20-byte heap allocations and very slow search times due to the tree's height. So the original intension was to reduce memory fragmentation and improve search times. The B+ tree solves this by packing multiple data pairs into one node with a large number of descendant nodes.
In computer science lectures it is often stated that using consecutive bytes in memory would be more cache-efficient, because the CPU's cache levels always fetch larger blocks from main memory. So it would be best to store the keys of a node in one continuous array. This way the inner scanning loop would be accelerated by benefiting from cache effects and pipelining speed-ups. Thus the cost of scanning for a matching key would be lower than in a red-black tree, even though the number of key comparisons are theoretically larger. This second aspect aroused my academic interest and resulted in the speed test experiments.
A third inspiration was that no working C++ template implementation of a B+ tree could be found on the Internet. Now this one can be found.
Implementation Overview
This implementation contains five main classes within the stx namespace (blandly named Some Template eXtensions). The base class btree implements the B+ tree algorithms using inner and leaf nodes in main memory. Almost all STL-required function calls are implemented (see below for the exceptions). The asymptotic time requirements of the STL standard are theoretically not always fulfilled. However in practice this B+ tree performs better than the STL's red-black tree at the cost of using more memory. See the speed test results for details.
The base class is then specialized into btree_set, btree_multiset, btree_map and btree_multimap using default template parameters and facade functions. These classes are designed to be drop-in replacements for the corresponding STL containers.
The insertion function splits the nodes on recursion unroll. Erase is largely based on Jannink's ideas. See http://dbpubs.stanford.edu:8090/pub/1995-19 for his paper on "Implementing Deletion in B+-trees".
The two set classes (btree_set and btree_multiset) are derived from the base implementation class btree by specifying an empty struct as data_type. All functions are adapted to provide the base class with empty placeholder objects. Note that it is somewhat inefficient to implement a set or multiset using a B+ tree: a plain B tree (without +) would hold no extra copies of the keys. The main focus was on implementing the maps.
Problem with Separated Key/Data Arrays
The most noteworthy difference to the default red-black tree implementation of std::map is that the B+ tree does not hold key/data pairs together in memory. Instead each B+ tree node has two separate arrays containing keys and data values. This design was chosen to utilize cache-line effects while scanning the key array.
However it also directly generates many problems in implementing the iterators' operators. These return a (writable) reference or pointer to a value_type, which is a std::pair composition. These data/key pairs however are not stored together and thus a temporary copy must be constructed. This copy should not be written to, because it is not stored back into the B+ tree. This effectively prohibits use of many STL algorithms which writing to the B+ tree's iterators. I would be grateful for hints on how to resolve this problem without folding the key and data arrays.
Test Suite
The B+ tree distribution contains an extensive test suite using cppunit. According to gcov 90.9% of the btree.h implementation is covered.
STL Incompatibilities
Key and Data Type Requirements
The tree algorithms currently do not use copy-construction. All key/data items are allocated in the nodes using the default-constructor and are subsequently only assigned new data (using operator=).
Iterators' Operators
The most important incompatibility are the non-writable operator* and operator-> of the iterator. See above for a discussion of the problem on separated key/data arrays. Instead of *iter and iter-> use the new function iter.data() which returns a writable reference to the data value in the tree.
Erase Functions
The B+ tree supports three functions:
size_type erase(const key_type &key); // erase all data pairs matching key bool erase_one(const key_type &key); // erase one data pair matching key void erase(iterator iter); // erase pair referenced by iter
The following STL-required function is not supported:
void erase(iterator first, iterator last);
Extensions
Beyond the usual STL interface the B+ tree classes support some extra goodies.
// Bulk load a sorted range. Loads items into leaves and constructs a // B-tree above them. The tree must be empty when calling this function. template <typename Iterator> void bulk_load(Iterator ibegin, Iterator iend); // Output the tree in a pseudo-hierarchical text dump to std::cout. This // function requires that BTREE_DEBUG is defined prior to including the btree // headers. Furthermore the key and data types must be std::ostream printable. void print() const; // Run extensive checks of the tree invariants. If a corruption in found the // program will abort via assert(). See below on enabling auto-verification. void verify() const; // Serialize and restore the B+ tree nodes and data into/from a binary image. // This requires that the key and data types are integral and contain no // outside pointers or references. void dump(std::ostream &os) const; bool restore(std::istream &is);
B+ Tree Traits
All tree template classes take a template parameter structure which holds important options of the implementation. The following structure shows which static variables specify the options and the corresponding defaults:
struct btree_default_map_traits { // If true, the tree will self verify it's invariants after each insert() // or erase(). The header must have been compiled with BTREE_DEBUG // defined. static const bool selfverify = false; // If true, the tree will print out debug information and a tree dump // during insert() or erase() operation. The header must have been // compiled with BTREE_DEBUG defined and key_type must be std::ostream // printable. static const bool debug = false; // Number of slots in each leaf of the tree. Estimated so that each node // has a size of about 256 bytes. static const int leafslots = MAX( 8, 256 / (sizeof(_Key) + sizeof(_Data)) ); // Number of slots in each inner node of the tree. Estimated so that each // node has a size of about 256 bytes. static const int innerslots = MAX( 8, 256 / (sizeof(_Key) + sizeof(void*)) ); // As of stx-btree-0.9, the code does linear search in find_lower() and // find_upper() instead of binary_search, unless the node size is larger // than this threshold. See notes at // https://panthema.net/2013/0504-STX-B+Tree-Binary-vs-Linear-Search static const size_t binsearch_threshold = 256; };
Speed Tests
See the web page https://panthema.net/2007/stx-btree/speedtest/ for speed test results and a discussion thereof.
ChangeLog
- btree.h: changing
find_lower()to not use binary search for small node sizes. More about this on my blog. - btree.h: implementing
bulk_load()to construct a B+ tree from a pre-sorted iterator range. - btree.h: replacing copy loops with
std::copycalls. - btree.h: added template parameter
UsedAsSetto skip copying of one bytevalue_typearrays in set container specializations. - license: changing template header source code license to Boost License, and the rest to GPLv3.
- memprofile: using
malloc_countto create a memory profile of map containers. - speedtest: many changes to also include
tr1::unordered_setand to run both map and set container tests. - testsuite: removing
cppunitand using enclosedtpunit++instead.
- speedtest: added results of new speed test run in 2011 and also appended notes to old speed test doxygen page.
- btree.h, others.h: implementing
erase(iterator)using recursive depth first search for the referenced leaf node.
- btree.h: Correcting documentation of
lower_bound()andupper_bound(). The functions themselves were correct. - btree.h: Applying STL allocator patch contributed by MH.
- btree.h: Correcting limits of for loop to shift pairs from left to right leaf nodes during deletion.
- speedtest.cc: Modifying speedtest to also test the hash table container implementation from
__gnu_cxx. Extending tests by another set of runs measuring only the find/lookup functions.
- btree.h: Fixing crash when running
verify()on an empty btree object. Now the root node is freed when the last item is removed. Also fixing crash when attempting to copy an empty btree or when trying to remove a non-existing item from an empty btree.
- btree.h: Replacing many
/ 2integer divisions with>> 1as suggested by received e-mails. This may or may not improve speed. I personally doubt it, because modern compilers should optimize these simple instructions.
- btree.h: Completely reworked
reverse_iteratorclasses. Now they are real implementations and do not use STL magic. Bothreverse_iteratorandconst_reverse_iteratorshould work as expected now. Added two large test cases for iterators. Also enabling public Default-Constructor on iterators.
- btree.h: Fixing up a memory access bug which happens in
leaf->slotkey[leaf->slotuse - 1]ifleaf-slotuse == 0. This doesnt have any other bad effect, because the case only occurs whenleaf == rootand thus thebtree_update_lastkeymessage is never really processed. However it still is a bad-memory access.
- btree.h: Fixed a valgrind-detected bug based on a new test case received via email. During the
find()functionfind_lower()is called and returns the slot number with the smallest or equal key. However if the queried key is larger than all keys in a leaf node or in the whole tree,find_lower()returns a slot number past the last valid key slot. Comparison of this invalid slot with the queried key then yields an uninitialized memory error in valgrind.
- btree.h: Fixed segfault in
print()because of non-existing root. Fixed segfault inend()when the tree is totally empty. AddedBTREE_FRIENDSmacro so that wxBTreeDemo can access private members. Changing print function to output to a user-givenstd::ostream
Older Downloads
| STX B+ Tree Version 0.8.6 released 2011-05-18 | ||
| Source code archive: (includes Doxygen HTML) | stx-btree-0.8.6.tar.bz2 MD5: 552ca8419ce21b75af2fbb74aea4e253 | Browse online |
| ChangeLog | ||
| Extensive Documentation: | Browse documentation online | |
| STX B+ Tree Version 0.8.3 released 2008-09-07 | ||
| Source code archive: (includes Doxygen HTML) | stx-btree-0.8.3.tar.bz2 MD5: 1c13439c5d6ca6ba8bfce6b39f1ca65c | Browse online |
| ChangeLog | ||
| Extensive Documentation: | Browse documentation online | |
| STX B+ Tree Version 0.8.2 released 2008-08-13 | ||
| Source code archive: (includes Doxygen HTML) | stx-btree-0.8.2.tar.bz2 MD5: bf147a1f2f9a540d283244e5a92c5353 | Browse online |
| ChangeLog | ||
| Extensive Documentation: | Browse documentation online | |
| STX B+ Tree Version 0.8.1 released 2008-01-25 | ||
| Source code archive: | stx-btree-0.8.1.tar.bz2 MD5: 87df74dab5c5b2a34c6ebfbfc224b26b | Browse online |
| ChangeLog | ||
| Extensive Documentation: | stx-btree-0.8.1-doxygen.tar.bz2 MD5: f7801dd6e8672820a599704a7fd7df4f | Browse documentation online |
| STX B+ Tree Version 0.8 released 2007-05-13 | ||
| Source code archive: | stx-btree-0.8.tar.bz2 MD5: b3e2981dff63d9a01bfc0a102a49c32c | Browse online |
| ChangeLog | ||
| Extensive Documentation: | stx-btree-0.8-doxygen.tar.bz2 MD5: 7e14e8eb904129f77d96c8abb517068d | Browse documentation online |
| STX B+ Tree Version 0.7 released 2007-04-27 | ||
| Source code archive: | stx-btree-0.7.tar.bz2 MD5: b10da911facd14f4faa6f31b43fd0591 | Browse online |
| Extensive Documentation: | stx-btree-0.7-doxygen.tar.bz2 MD5: a4106a81fb5982a3bc5fcb822f85d219 | Browse documentation online |